A data-analysis AI agent read a natural-language prompt, generated Python code, and executed it to interact with the data, exactly as designed. That convenience was exploited as the flaw’s entry point.
In 2025, research documented CVE-2024-12366, a prompt-injection vulnerability inPandasAI that allowed attacker-supplied text to run arbitrary code, granting remote execution rights on deployed systems. (Note: The vendor has since released patches and security configurations to address this issue.)
CERT advisories VU#148244 and a Black Hat USA 2025 “From Prompts to Pwns” slides showed how easily a helpful agent can become an execution primitive.
That episode captured the tension perfectly; precision automation built on unpredictable context. In ethical hacking, the same autonomy that accelerates vulnerability discovery can blur the boundary between safe validation and unsanctioned exploitation.
The question grows sharper as the security industry considers tools, such as potential red-team agents, bug-bounty triage systems, and penetration-testing assistants that embed large-language-model agents: Should AI be trusted with ethical hacking?
This article examines that question through verifiable evidence, where AI helps, where it fails under adversarial pressure, operational drift, and reliability challenges, and how trust can be earned through governance, reproducibility, and human accountability.
Defining Trust in AI for Ethical Hacking
Security teams test tools to ensure they can trust them. The same principle applies to AI. So, what should we test or measure?
The NIST AI Risk Management Framework defines trustworthiness through recurring dimensions that determine whether an AI system can be relied upon under certain conditions. Five of those dimensions form the foundation for ethical-hacking use cases:
- Reliability (consistent, reproducible outputs)
- Resilience (resistance to manipulation)
- Transparency (auditable reasoning)
- Accountability (human oversight for all actions)
- Safety (no unintended harm)
LLMs produce probabilistic variance between runs (a reliability gap). The agentic architecture is more susceptible to adversarial inputs like prompt injection (a Resilience failure). The model’s internal reasoning path is not externally accessible (a transparency deficit), while the potential for unpredictable, emergent behavior complicates liability (an accountability void), and agents can execute unauthorized or destructive actions outside the intended sandbox (a safety risk).
These aren’t abstract concerns; they’re documented failure modes, mapped to MITRE ATLAS tactics and techniques. Trust must be demonstrated through reproducibility tests, for example, NIST’s Test, Evaluation, Verification, and Validation (TEVV) cycle, not declared through marketing claims.
Where AI Helps Today
The previous section established the foundational dimensions for AI trustworthiness. This raises a critical question: Given the AI’s documented risks, why use AI at all? Especially in Ethical hacking.
AI is increasingly used to manage the scale and complexity of modern security data. AI’s core value is automating repetitive and large-scale penetration-testing and bug-bounty tasks, expanding and cleaning noisy inputs, orchestrating tools under guardrails, and packaging evidence so humans can review and decide the next step. This frees human experts to focus on high-value, complex judgments.
Let’s look at how that plays out in practice, through tools, platforms, and research projects already using AI.
Security Tools Assisting Within Workflows
AI normalizes scanner and reconnaissance outputs (de-duplicating results and clustering look-alike findings) and drafts HTTP request templates/payload variants and minimal PoC steps, then presents them for human approval. It also turns raw logs or HTTP traces into reproducible steps. PortSwigger positions Burp AI‘s agentic features, which augment testers, not replace them.
The same pattern appears in PentestGPT (USENIX Security paper), which formalizes a Parsing → Reasoning → Generation loop to extract essentials from tool output and web artifacts before proposing operator actions.
Bug Bounty and AI
According to vendor documentation, platforms such as Bugcrowd embed AI within human-in-the-loop (HITL) triage. Bugcrowd AI Triage/AI Connect uses AI with human oversight to filter duplicates/spam, accelerate escalation, document reproduction steps for customers, and provide curated vulnerability data to contextualize fixes.
HackerOne Hai Triage pairs AI with analyst review to remove low-signal reports, surface higher-impact issues, and support clearer hand-offs to customers.
AI assists bug hunters, too. As of October 2025, the official HackerOne Collectives leaderboard lists “xbow”, an AI-agent-based security collective, at the top of the U.S. view. HackerOne’s public documentation explains that rankings are driven by reputation, signal, and impact, which is useful as a signal of sustained and validated contribution. (Leaderboards overview; Reputation explainer).
PTaaS and Agentic AI
Synack’s Sara, part of the company’s Active Offense platform, shows what happens when that idea scales: an agentic AI helps identify, validate, and prioritize vulnerabilities, while human testers perform final exploitation and verification.
The Common Pattern
Across these implementations, there is one common trait: explicit human-in-the-loop control. This is aligned with the OWASP LLM Top 10 (2025) guidance, particularly the directives to mitigate LLM01 (“Prompt Injection”) and LLM06 (“Excessive Agency”).
That consistency leads to the next question: Can AI ever be trusted in ethical hacking without HITL controls? The following section examines the other face of the AI “help” coin.
Where AI Fails
Let’s look at where things break in practice, mapped to trust dimensions, public evidence, and documented incidents.
Scope Violation and Prompt Injection
As shown earlier with PandasAI (CVE-2024-12366), public reports have documented evidence that natural-language inputs can be converted into executable code. A malicious prompt can steer an AI agent into unsafe actions such as executing arbitrary Python code on the host. And this case violates NIST AI RMF’s Safe and Secure and Resilient trust dimensions. It’s not a niche case; OWASP’s Top 10 for LLM Applications (2025) lists prompt/indirect injection as a first-order risk, and MITRE ATLAS classifies LLM Prompt Injection as AML.T0051.
Zero-Click and Indirect Injection
EchoLeak showed that hidden instructions/prompts in email content could make Microsoft 365 Copilot exfiltrate contextual data with no user interaction, a scope violation caused by background automation. And this case threatens NIST AI RMF’s Secure and Resilient and Privacy-Enhanced trust dimensions. Also, it demonstrates how background automation bypasses human approval. (For broader context on real-world misuse patterns, see OpenAI’s Oct-2025 threat report.)
The same indirect-injection pattern can compromise a pentest agent if it ingests tainted context.
Environmental Poisoning
Not all failures are in the model; many live in the context fed to it. Tenable’s “Gemini Trifecta” documented a now-remediated chain where poisoned logs, browser history, and cloud metadata subverted guardrails. An ATLAS Model Influence (AML.T0043) event where the model didn’t break; its context did. And this case threatens NIST AI RMF Secure and Resilient and Privacy-Enhanced trust dimensions.
The same risk applies to on-premises or custom assistants reading internal wikis, ticketing systems, or telemetry: a single poisoned page can redirect an agent’s reasoning. According to MITRE ATLAS AML.T0020, adversarial data can redirect model behavior in ways that are difficult to detect, yet catastrophic for safety and reproducibility.
Operational Drift and Reliability Failures
LLMs are probabilistic: same prompt, different runs, different results. In agents and penetration testing agents specifically, this non-determinism amplifies through tool flakiness (timeouts, parsing errors, brittle regexes), producing false positives (“vulnerabilities” humans can’t reproduce) and false negatives (missed issues because intermediate steps silently failed).
The described non-determinism implicates NIST AI RMF 1.0 Valid and Reliable trust dimensions, which is why the framework focuses on reliability and reproducibility, and why NIST TEVV exists, to ensure results are testable, repeatable, and logged end-to-end.
Research echoes this: AutoPenBench benchmarks showed that human-assisted agents completed 64 % of penetration tasks compared with 21% for fully autonomous agents under identical test conditions.
The Pattern
Across these categories and examples, AI agents act confidently in compromised or unstable contexts, whether the context is attacked (injection/poisoning) or simply brittle (variance, tools). They hallucinate authority and misread scope.
That sets up the next sections: governance that limits agency and measurement that proves behavior (TEVV).
Governance: The Necessary Path to Trust
Section 3 showed how agents fail under pressure, prompt injection, poisoned context, and operational drift. These kinds of risks aren’t entirely novel, but three critical differences require adapted AI governance:
- Classic tools like Nmap are deterministic, while AI has a probabilistic nature, fundamentally complicating reproducibility.
- Scanner signatures (e.g., Nessus) are auditable, whereas billions of AI model parameters resist inspection.
- Exploiting a tool or application requires traditional technical attacks, while jailbreaking AI targets the semantic layer, a surface that traditional controls (e.g., WAF/EDR) do not directly cover.
How to Govern
- Control the Trigger
Eliminate background or queued execution; Bind every network- or system-affecting action to explicit human approval. This directly counters injection-driven scope violations captured in OWASP LLM01 (Prompt Injection) and LLM06 (Excessive Agency). As Black Hat USA 2025 briefing showed, risk rises with autonomy; approvals must be visible and blocking.
- Constrain the Tool
Expose only allowlisted tools with bounded parameters and safe defaults. Treat tool I/O as tainted until validated. This narrows the path from prompt to side-effects and constrains model-influence pivots (MITRE ATLAS AML.T0051, AML.T0043). Default-deny dangerous operations and require context checks before any privileged calls.
- Audit and Control
Log at high fidelity: prompts, retrieved context, tool calls with parameters, outputs, and who approved which action. Maintain kill-switches to revoke tokens and halt agents mid-flow. These are emphasized in NIST AI RMF 1.0 “Measure/Manage” functions and TEVV-style oversight.
Supply-chain transparency: Document models, adapters, datasets, and provenance through AI/ML Bill of Materials (NIST AIBOM guidance; CycloneDX ML-BOM). Each external artifact becomes verifiable, not blindly trusted.
- Continuously Test
Make TEVV a habit, not an event. Rerun adversarial cases mapped to the OWASP LLM top 10 after any update. Verify controls still hold. Frameworks like Microsoft PyRIT structure red-team exercises, use them as methodology, not performance metrics.
Governance isn’t the brake, it’s the steering system, keeping Reliability, Robustness, Transparency, Accountability, and Safety intact at operational tempo.
Next, Section 5 shows why “trusted” means tested; measurement turns controls into evidence over time.
Measuring What Matters
In NIST AI RMF 1.0, measurement is continuous evidence generation, operationalized through TEVV test, evaluation, validation, and verification; applied to each AI-assisted workflow.
Reproducibility
Aim for procedure-level repeatability rather than bit-identical outputs: version prompts, seeds, tools, and data snapshots; define acceptable variance bands. External evaluations like CyberSecEval 3 show current models remain sensitive to prompt/context shifts; another reason to re-test before and after updates.
Adversarial Evaluation
Select risks from OWASP Top 10 for LLM Applications and instantiate cases with MITRE ATLAS; e.g., AML.T0051 Prompt Injection, AML.T0043 Model Influence, AML.T0020 Data/Model Poisoning; then track adversarial pass rate alongside functional accuracy.
Evidence Logistics
Preserve the artifacts required to rerun: inputs, retrieved context, tool/parameter versions, seeds, approvals, outputs; the practical backbone of TEVV (NIST TEVV).
Reading claims treat numbers as hypotheses. Four fields make them decision-grade: task definition, autonomy level, verification method, and rerun evidence; without these, figures are weak signals.
So what? Measurement isn’t finality; it’s maintenance. The goal is bounded, evidenced behavior that withstands reruns and adversarial tests and holds up after the next change.
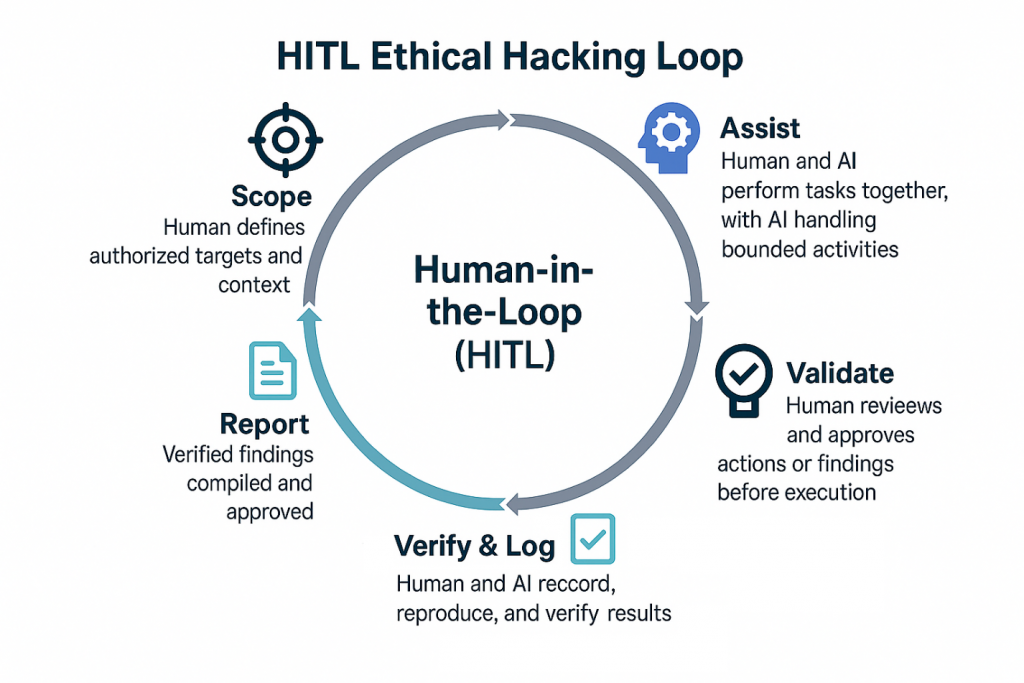
Figure 1. HITL Ethical Hacking Loop — Scope, Assist, Validate, Log & Verify, Report.
The loop visualizes governed, reproducible AI collaboration in ethical hacking, where human oversight, verification, and accountability maintain control over automation.
This sets up the verdict: trust remains conditional on what the evidence shows.
Verdict: Not Autonomously; Yes, Conditionally
Should AI be trusted with ethical hacking? Based on the public evidence and first-principles frameworks, the answer is conditional yes. Trust emerges when automation is bounded, observable, and reproducible.
In governed mode, AI really helps, while approvals, sandboxes, and safe defaults keep impact tied to human judgment. Logging closes the loop by capturing prompts, retrieved context, parameters, tool calls, outputs, and who approved which action. Measurement keeps trust alive. TEVV is not an audit; it is a habit. Re-test the mapped, deployment-specific risks whenever models, tools, data, or context change. Trust isn’t a finish line; it’s maintenance.
Autonomy may improve, but the accountability model does not change. The reliable pattern remains human-led, AI-assisted: machines propose and accelerate; people decide and own the outcome.
The future belongs to human-led, AI-assisted teams that combine machine efficiency with accountable judgment. The smartest AI still needs supervision. Technology will mature; the responsibility will not. The aim is balance: governance must be strong enough to ensure safety, yet light enough to preserve speed and innovation. Governance keeps that balance measurable, repeatable, and reversible, the enduring test of trust.