Evaluation frameworks for Large Language Models (LLMs) are systematic approaches to assessing the performance, capabilities, and limitations of these models. The growth in size and capability of the LLMs and the rise of powerful Small Language Models (SLMs) have reinforced the need for robust evaluation frameworks to ensure their reliability, fairness, and alignment with intended uses.
While the current status of maturity in LLM evaluation frameworks is evolving rapidly, there are still significant challenges and limitations that need to be addressed to ensure that LLMs can be deployed with confidence and responsibly.
Given the regulatory frameworks, such as the EU AI Act in Europe and the NIST AI Risk Management Framework in the US, understanding the performance of LLMs using production workloads is a strategic imperative.
In this article, we will explore the current metrics widely used for LLM evaluations, key challenges that need to be overcome, and how Golden Evaluation Data Sets can be used for fine-tuning the metrics for industry-specific domains.

Essential Metrics for Assessing LLM Performance
The field of LLM evaluation is progressing rapidly. Researchers are developing new benchmarks for language understanding, question-answering data sets, and standardized evaluation frameworks.
Outlined are some of the current metrics widely used for evaluating the performance of LLMs. Retrieval Augmented
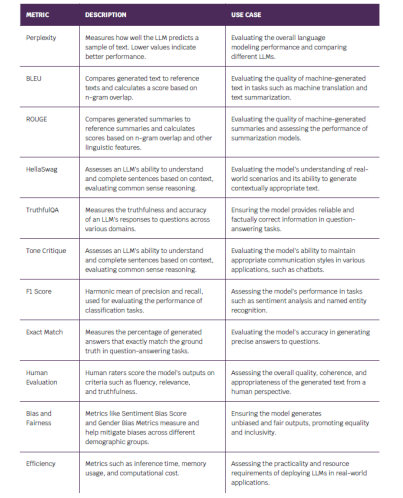
Generation (RAG) techniques are gaining a lot of traction to address the issues of personalization and falling out of data inherent with current LLMs.
There is ongoing research on how RAG techniques can be used for toxicity migration and mitigating drift over time by using these retrieval methods.
Challenges with Current LLM Evaluation Frameworks
Evaluating Large Language Models (LLMs) poses several challenges that researchers and developers continually strive to address. These challenges stem from the models’ complexity, the breadth of their potential applications, and the evolving landscape of AI technology. Some of the current challenges include:
Lack of Standardization: There is no universally accepted set of benchmarks or metrics for evaluating LLMs, making it difficult to compare performance across different models. This lack of standardization can hinder the development of models that are optimally tuned for specific tasks or ethically aligned outputs.
Bias and Fairness: LLMs can inherit and even amplify biases present in their training data. Identifying and mitigating these biases without reducing the model’s effectiveness is a complex challenge. Ensuring fairness and avoiding discrimination in model outputs across diverse demographic groups remains a critical concern.
Evaluating Generalization and Reasoning: Measuring an LLM’s ability to generalize to new situations, domains, or tasks beyond its training data is difficult. Similarly, assessing the model’s reasoning capabilities, especially in complex or abstract contexts, is challenging due to the subjective nature of what constitutes “good” reasoning.
Interpretability and Explainability: As LLMs grow in complexity, understanding why a model produces a particular output becomes increasingly difficult. This lack of transparency can be a significant issue in sensitive applications where understanding the decision-making process is crucial.
Robustness and Security: Evaluating and ensuring the robustness of LLMs against adversarial attacks (inputs designed to confuse or trick the model) is a complex challenge. Ensuring that models are secure and cannot be exploited to generate harmful or misleading content is of paramount importance.
Resource Intensity: The computational resources required to train and evaluate large-scale LLMs are substantial. This not only includes the direct computational costs but also environmental considerations. Making evaluation processes more efficient without compromising on thoroughness is a key challenge.
Human Evaluation Integration: Incorporating human judgment into the evaluation process can help capture the nuances of model outputs in ways that automated metrics will find difficult to handle.
However, designing effective and scalable human evaluation frameworks that can be integrated with automated methods is challenging.
Domain-Specific Evaluation: Developing metrics and benchmarks that accurately reflect performance in specific domains (e.g., legal, medical, or creative writing) requires deep domain knowledge and collaboration. This is essential for LLMs to be reliably used in specialized applications.
Ethical and Societal Implications: Beyond technical performance, evaluating the ethical implications and potential societal impacts of LLMs is a multifaceted challenge. This includes ensuring that models do not perpetuate harmful stereotypes or misinformation.
Some of these challenges could be effectively addressed through standardization and collaboration, transparency in model development, adversarial testing to assess their robustness against unexpected inputs or manipulation, incorporating feedback loops, and human augmentation in the evaluation lifecycle.

Creating Golden Evaluation Sets for Business Impact
As businesses increasingly leverage Large Language Models (LLMs) to enhance their operations, the importance of tailored evaluation becomes paramount. While academic benchmarks provide a solid foundation, they may not fully encompass the nuanced challenges unique to each business. To bridge this gap, companies can focus on crafting golden evaluation sets that precisely reflect their specialized business environments.
Understanding Golden Evaluation Sets
A golden evaluation set is a meticulously curated dataset used as a standard for model evaluation. It consists of high-quality, annotated data that accurately represents the real-world scenarios a business model will encounter.
This set serves as the ‘gold standard’ against which an LLM’s output is compared, ensuring that the evaluation is relevant and rigorous.
Need for Business-Specific Sets
Generic datasets may overlook industry-specific jargon, workflows, and customer interactions. By building a golden set that mirrors a company’s unique environment, businesses can better gauge how effectively an LLM understands and processes the language and tasks critical to their operations. Collecting your gold standard data and using it for cross-comparisons over time can be an effective strategy. In this case, it is imperative to avoid using this data to fine-tune your model.
Crafting a Golden Set
Creating a golden evaluation set involves several steps:
Data Collection: Gather a diverse and comprehensive collection of data samples from actual business processes, like customer service interactions, reports, or transaction records.
Annotation: Employ experts to annotate the data, ensuring that it reflects the complexity and context-specific nuances of your business domain.
Validation: Implement rigorous validation processes to ensure the quality and reliability of the annotations, including cross-referencing and consensus methods.
Relevance Check: Regularly review and update the golden set to keep it aligned with evolving business needs and linguistic patterns.
Advantages of Custom Evaluation Sets
Custom evaluation sets allow for targeted performance insights, revealing how well an LLM serves in specific business roles, from customer service bots to financial advisory systems. These insights can drive targeted improvements, enhance customer experience, and provide a competitive edge.
Challenges in Creation
Creating these sets can be resource-intensive, requiring time, expertise, and maintenance. However, the investment pays off by providing clear insights into model performance and guiding the development of more effective AI-driven solutions.

LLM-Based Evaluation: Leveraging AI to Assess AI
While we have discussed some of the current challenges with evaluation frameworks earlier, there is ongoing research into innovative new techniques. Researchers are exploring a new approach, known as LLM-based evaluation or machine-machine evaluation.
This involves using one LLM to assess the performance, quality, and characteristics of another LLM’s outputs.
Recent research has shown promising results in using LLMs for tasks such as:
Quality Assessment: LLMs can be trained to evaluate the fluency, coherence, and overall quality of text generated by other LLMs. By comparing the generated text to human-written references or established quality metrics, LLMs can provide automated assessments of language quality.
Consistency Checking: LLMs can be employed to identify inconsistencies, contradictions, or factual errors in the outputs of other LLMs. By leveraging their own knowledge bases and reasoning capabilities, evaluator LLMs can flag potential issues and help improve the consistency of the evaluated models.
Bias Detection: LLMs can be fine-tuned to detect and quantify biases present in the outputs of other LLMs. By analyzing generated text for patterns of discrimination, stereotyping, or unequal representation, evaluator LLMs can aid in identifying and mitigating biases in language models.
Comparative Analysis: LLMs can be used to compare the performance of multiple language models on specific tasks or datasets. By generating comparative reports or scores, evaluator LLMs can provide insights into the strengths and weaknesses of different models, aiding in model selection and benchmarking.
LLM-based evaluations offer several advantages over traditional evaluation methods, including the ability to generate detailed and nuanced assessments, cost-effectiveness, unbiasedness, and holistic evaluation. However, it is crucial to recognize that LLMs themselves may have biases or limitations, and their evaluations should be interpreted cautiously. Researchers are actively working on refining these techniques and developing best practices for reliable and unbiased LLM-based evaluation.
LLM Evaluation Toolkit: Ensuring Performance and Integrity A robust LLM deployment
extends beyond model development, diving deep into the realms of evaluation,
monitoring, and observability.
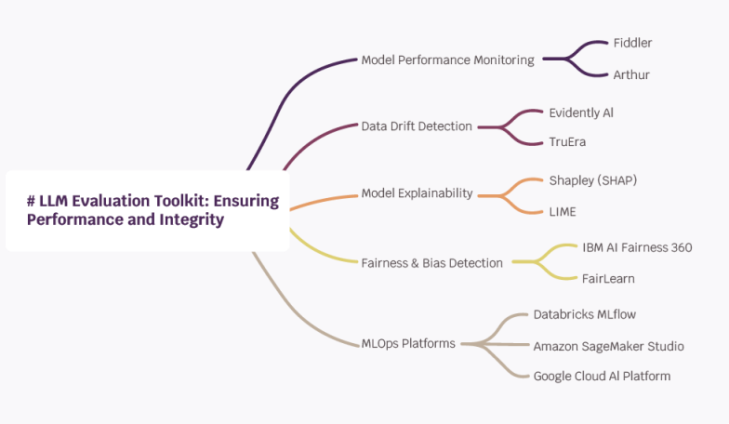
This critical layer of the AI software stack ensures models perform as intended, remain accurate over time, and adhere to ethical guidelines. Let us explore the essential tools and platforms that underpin this vital phase.
Model Performance Monitoring
Ensuring your LLM maintains its efficacy post-deployment is crucial. Tools like Fiddler and Arthur provide comprehensive monitoring solutions, tracking model performance in real time to catch any deviations or degradation in output quality. This vigilance allows for prompt interventions, keeping models at their peak.

Data Drift Detection
As the world changes, so does the data underlying our models. Evidently AI and TruEra specialize in detecting shifts in data patterns—known as data drift—alerting you to changes that may affect model accuracy. Timely detection enables quick updates to keep models relevant and reliable.
Model Explainability
Understanding the ‘why’ behind model predictions is key to trust and transparency. Shapley (SHAP) and LIME offer insights into the decision-making processes of your models, demystifying AI operations. This explainability fosters confidence among users and stakeholders, ensuring models are not just effective but also understandable.
Fairness and Bias Detection
AI must be equitable. Tools like IBM AI Fairness 360 and FairLearn assess models for bias and fairness, helping to identify and mitigate unintended prejudices in model predictions. This commitment to fairness ensures that LLM deployments contribute positively to all users, regardless of background.
MLOps Platforms
Operational excellence in AI requires sophisticated orchestration and management.
Databricks MLflow, Amazon SageMaker Studio, and Google Cloud AI Platform stand out as comprehensive MLOps platforms, facilitating seamless model lifecycle management from development to deployment and monitoring. These platforms serve as the backbone of efficient, scalable AI operations.
By integrating these tools into the LLM deployment process, organizations can not only optimize performance but also ensure their models are observable, explainable, and ethically sound. This holistic approach to model management underscores the commitment to deploying responsible AI, marking a pivotal step forward in the journey of LLM evaluation and deployment.
Enhancing LLM Evaluation with Human Insight
Quantitative metrics shine a light on LLM performance, but the full story requires the nuanced understanding that only human evaluators can provide. As LLMs evolve, so do the challenges of bias, hallucinations, and inaccuracies, which can distort the output of the models and lead to misleading or harmful content. Integration of human judgment offers a critical balance, ensuring LLMs resonate with reality. Human evaluators excel in identifying biases and inaccuracies, grounding AI outputs in truth and ethical considerations. This human-centric approach involves:
- Crafting detailed guidelines for evaluators, emphasizing accuracy, coherence, and ethical integrity.
- Assembling diverse evaluation teams to bring a broad spectrum of perspectives and reduce subjective biases.
- Establishing continuous feedback mechanisms to refine LLMs based on human insights.
- Creating oversight protocols for critical applications, ensuring AI aligns with ethical standards and societal values.







