Well before being accelerated by the current crisis, digitalization has been driven by the need to harness change for competitive advantage. The key to future prosperity in the online economy is recognized as a need for trustworthy networks and IT systems. This demand for trustworthiness is driving ever higher standards of maturity in cyber-risk management and both commercial and regulatory compliance. It is increasingly commonplace for organizations to be operating in a multi-regulatory environment in which audits become more frequent and numerous, and subject to higher levels of scrutiny with each passing year.
Maintaining continual compliance is extremely onerous. Organizations typically respond by first streamlining their operations: teams dedicated to specific compliance framework silos are re-organized into a single, enterprise-wide capability. They then find out that despite these efficiency savings, they are still left with a task of formidable scope and complexity that requires a small army to support what is still a largely manual operation. It is clear that automation will be a key enabler to further progress, but it is not possible to automate anything without a very precise understanding of the problem domain.
Why Is Compliance Such a Headache?
The management of enterprise IT systems, even before considering the security aspects, faces a set of complex, multi-faceted, even “wicked” problems. The task being asked of compliance introduces a further set of factors:
- Control objectives
- Control requirements
- Control measures
- In-scope components
- Risk factors
- Implementation guidelines
- Alternative implementations
- Deviations
- Mitigations
- Remediation
- Systems/Firewalls/Gateways
- Network Zoning/Architectures/Topologies
- Application owners
- System owners
- Evidence acceptability criteria/QA
- Evidence collection and audit procedures
How are compliance teams equipped to respond to this multi-dimensional challenge? Usually with spreadsheets, a war-room tiled in sticky notes, and a process all too prone to becoming over-complex, chaotic, expensive, slow, morale-sapping, inconsistent, opaque, poorly-defined and understood, contra indicatory, inflexible, and of limited reuse.

What If This Could Be Automated?
The benefits of some kind of automated analytic capability for compliance are easily imagined:
- Improved efficiency, effectiveness, repeatability, and assurance with which the current compliance status can be determined
- The ability to monitor compliance status and audit readiness, not as an annual exercise, but on a continual basis
- Early identification (and remediation) of compliance issues
- The ability to run “what-if” scenarios (e.g., the impact of a particular change to an IT system, the granting of a policy exception, or a projection of what the compliance posture would be at some time in the future)
Currently, the creation of such a capability is a major undertaking for which very few organizations have the necessary skills, resources, and mandate. To be attainable as a mainstream best practice, the approach must evolve on a number of fronts:
- A means of representing and exchanging the necessary data in a defined and consistent format (ontologies, schema, standards bodies, etc.)
- Tools and techniques that support the creation and processing of artefacts expressed in this standard format
- Data analytics platforms capable of applying “intelligence” to visualize and extract knowledge from these data models
- A community of subject-matter experts and practitioners that have learned how to extract optimum value from (and avoid the limitations of) tools and techniques
- Early adopters willing to engage in pilot projects that provide feedback about which analytic functions prove most useful, which should be developed next, help explore and advance the capability, not only in the automation of compliance but also in related domains such as risk
Automation on the Horizon
The most significant development in this field for decades is NIST’s Open Security Controls Assessment Language (OSCAL). OSCAL defines a series of interlocking data schema that progressively define the stages of a compliance process: “Security Control Framework”, “Component Protection Profile”, “Architectural Pattern and Reference Architecture”, “Assessment Execution” and “Reporting”.
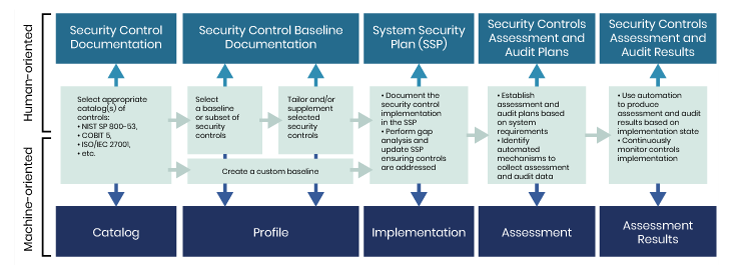
Figure 1 depicts the five stages of OSCAL’s data processing pipeline in which artefacts on the left are successively transformed and combined with those to their right. Conceptually, the Control Catalog is first overlaid onto a set of Protection Profiles (for components present in the target domain) to generate the applicable Baseline Control set.
The baselines are then arranged into architectural models (built from patterns, through reference architectures to Target Systems) to create an aggregate System Security Plan (SSP). The fourth stage defines the evidence generated by each of these controls and the fifth involves the evaluation of that evidence against the acceptance criteria required for compliance. The vertical axis of the architecture diagram shows that although OSCAL is natively a machine-readable format intended for automated processing, it is also meant to be rendered into human-oriented formats (e.g., MS Office or PDF) to facilitate process management and reporting. Aside from its technical vision, with the standing and resources of NIST behind it, the final pre-release of OSCAL (June 2020) is already established as a de-facto standard, with the full v1.0 release expected early next year.
How to Start Automating
Accomplished as it is, OSCAL only provides a data definition layer. To become operational, practical “OSCAL-enabled” tools are required to handle complex interlocking sets of large XML documents. Two types of tool are needed
- Human-oriented OSCAL-aware editors used to create the artefacts that define the end-to-end pipeline in a specific organizational context
- Analytical engines capable of processing OSCAL artefacts in their machine-readable form, ideally in both ad-hoc, discovery mode, and via predefined analysis suites that produce formatted audit reports
Regarding the former, the unidirectional rendering to human formats shown in Figure 1 is ill-adapted to the “round-trip” processes of a real documentation life cycle: the creation, review, tailoring, merging, test, validation, and approval of artefacts are best performed using formats better suited to human cognitive processing than raw XML. What is needed here is a human-oriented format that can be transformed into OSCAL (as well as vice versa).
A strong contender in this space is The Open Group’s Architecture modeling language, ArchiMate®. Not only is ArchiMate a visual language (light cognitive load), its tools are designed to facilitate the documentation of complex, highly-interconnected systems as a set of tailored stakeholder views. Because all views are built upon a single, coherent underlying model, these diagrams always maintain their consistency. Best of all, all certified ArchiMate tools export models in a standard XML Exchange Format so roundtrip conversions with OSCAL are fairly straightforward.
The only aspect of ArchiMate that is under-developed for this use-case is its ability to express the security perspective. Several core concepts such as Principal, Account, Asset, Control, or Trust, are not available in the standard vocabulary. Here we can turn to a joint initiative by The Open Group and security architecture specialists, The SABSA Institute, who are developing a Security Overlay that neatly fills this gap.
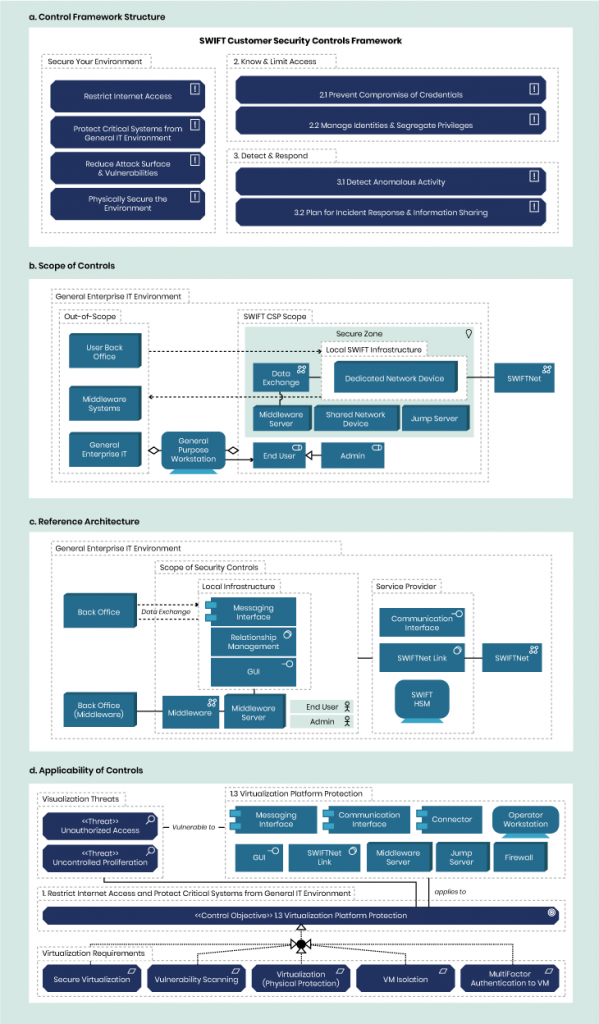
To illustrate the power of this approach, Figure 2 shows how the structure, scope, architectural patterns, and applicability of control requirements of a non-OSCAL Control Framework, (in this case the SWIFT Customer Security Programme1) can be faithfully reproduced in ArchiMate. It is this ability to refactor the multi-dimensional problem into a series of simple, mutually-consistent stakeholder views that brings manageability to the automation. Because ArchiMate is simultaneously a human- and machine-readable format, the boundary between the cognitive and automated processes becomes seamless.
Automated Analysis
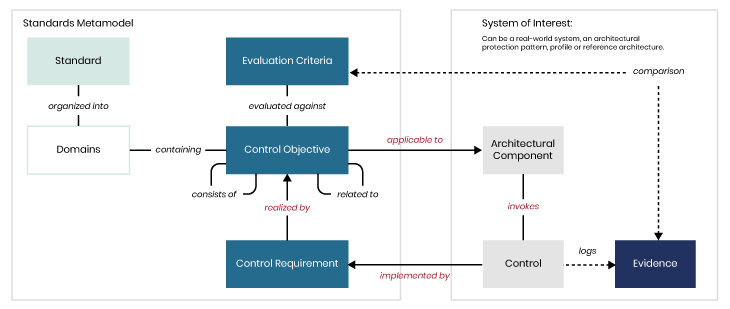
The OSCAL project has attracted broad participation, GRC tool vendors among them, but until mature, commercial OSCAL-enabled products reach the market, it is already possible to define and build basic analytical capabilities. The first step is to define a Compliance Metamodel like the one shown in Figure 3. On the left side (Standards Metamodel), we can define a Standard organized into Domains (like Figure 2a), each of which contain Control Objectives that can be realized through a set of Control Requirements with defined Evaluation Criteria. On the right-hand side, the metamodel of the Target System shows Architectural Components to which Control Objectives apply and Controls (physical, organizational, process, or technology) that implement the requirements and generate evidence.
Demonstrating compliance requires two predicates:
- First, there must be a “closed loop” path in the model that shows that the architectural component to which a control objective applies, is structurally/behaviorally dependent on controls that satisfy all requirements needed to realize the objective.
- There must then be evidence (e.g., audit logs) associated with each control that meets the evaluation criteria.
The compliance objective is met when, for all components to which it applies, a closed loop of requirements and controls can be found, supported by evidence that meets the criteria.
Running the Analysis
ArchiMate tools are available to suit all projects (and budgets). They focus on creating, maintaining, and publishing models but are limited when it comes to analysis. This goal can be reached with one final transformation: one that takes advantage of the natural synergy of ArchiMate (a well-defined ontology of elements and relationships) and the “nodes and edges” of a knowledge graph. Figure 4 shows an example knowledge graph of a multi-regulatory context: in this case the CSA Cloud Control Matrix and Questionnaire (the two green nodes on the left) mapped to the NIST SP800-53 (the green node center-right).

The knowledge graph has the opposite qualities of the ArchiMate model: visually, it is a typical “hairball” that serves little purpose (other than to highlight the futility of trying to capture the complexity of the domain in a spreadsheet!). It does however open the door to powerful analytics, business intelligence, and machine learning. It becomes possible to answer complex queries with a few lines of code. For example, “Which NIST requirements must an organization implement as the consumer of a SaaS application that has been certified against AICPA Trust Services Criteria? Which additional CSA questions should be put to the SaaS provider in order to extend our NIST compliance posture to the extended enterprise?”
Summary
The compliance landscape and environment are not going to get any easier. Organizations are facing increasingly complex and stringent regulations to which they must attest at greater frequency and at ever higher levels of scrutiny. Compliance teams need to get on top of this challenge to continue demonstrating their value to the organization.
Manual processes won’t scale.
Addressing each control framework as a silo does not scale. The economics of doing more with less demands a holistic enterprise-wide approach, but even with efficiency savings, the task remains formidable.
Automation is the next enabler.
Current approaches based on largely manual processes are wholly inadequate for the size and complexity of the task. Further progress towards ever-higher compliance standards, while containing costs, requires the support of tools and automation, of which little currently exists.
Breakthroughs are on the horizon.
By defining a data model of the compliance process, NIST’s OSCAL represents a game-changer for automation. It promises to make possible what has hitherto been a dream: continuous monitoring, constant audit readiness, and pre-emptive discovery of compliance issues. Although commercial tools are not yet on the market, it is time to start anticipating new approaches and techniques like the ones outlined in this article.







