The value Is in the system
Technologies rarely exist within a vacuum. We typically invent and build new technologies by using existing ones. IoT, big data, and the cloud are no exception to this rule. To illustrate this, let us examine the human body.
The human body is an amazing organism; a system of interconnected specialist parts. We have many different input devices. Our eyes and ears constantly feed data into our brain on what the world looks and sounds like. Our hands function both as input and output devices. Sensing objects as we hold them, identifying, protecting, and reacting to the information and meaning given from the brain, and then being able to output this as movement.
Typing this article is a great example. My hands on their own could not fulfil this function. They need instruction from my brain. This instruction is based on data that has been collected by my brain over many years. This data was consumed in the form of images, text, lectures, and personal practical experience, and is now stored somewhere in my brain.
When a person encounters new data, the information makes it’s way to the brain where it is combined with pervious knowledge to give it meaning. One can then decide on a course of action based on the initial data. The ability to give meaning to data based on past experience is commonly known as knowledge (see Diagram 1). We therefore have a very natural process of turning data into knowledge and ultimately into action.
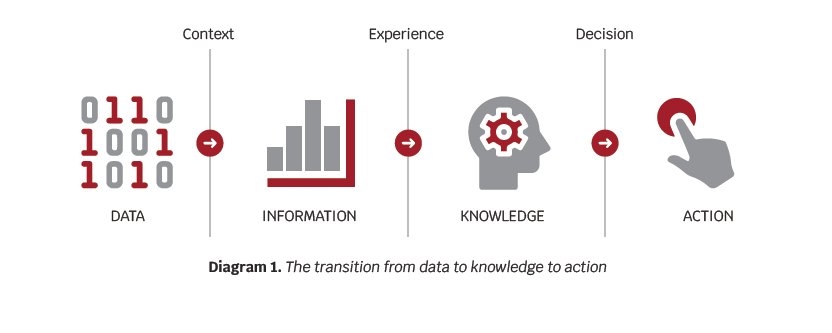
The relationship between big data, IoT (Internet of Things), and the cloud is almost identical to the previous example. Data only fulfils its purpose when it is analyzed and contextualized, thus becoming information. Add experience to information and you get practical knowledge.
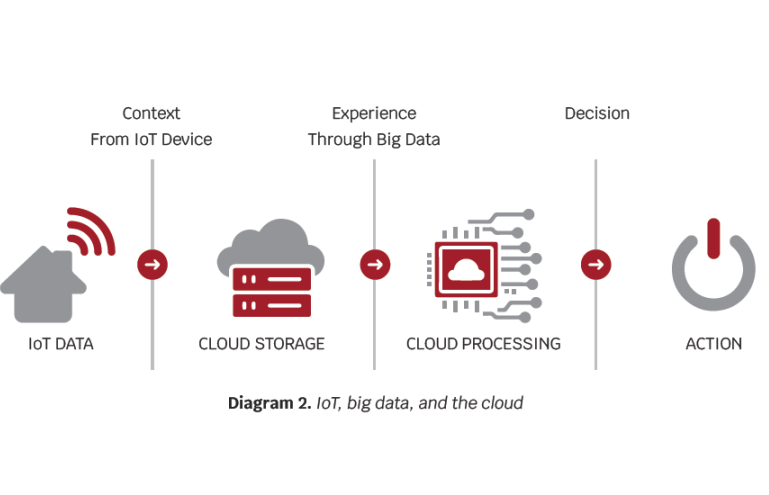
IoT devices collect data from their sources at the edge, this could represent movement, temperature, geolocation, time points, etc. The data then needs to go through storage and processing in order to get contextualized.
The following elements have the potential to create bottlenecks for an efficient flow of the process illustrated above.
- Internet connectivity
- Data storage
- Processing speed
- Actionability
The priority of these factors depends on circumstances. If, for example, we have to shut down a piece of machinery before it injures someone, then the connectivity and processing speeds are critical. For this reason, many IoT devices perform their own processing at the edge in order to perform immediate automated actions. Even in these cases, the models are generally created, analyzed, and updated in the cloud and then exported back to the IoT device, where decisions and actions happen.
There are several criteria that can be used to classify data, including origin and date of creation. Such classifications can then be used to compare one set of data with another one of the same criterion.
This is typically a machine learning process, where a prediction can be made based on a previously created model on one or several metrics obtained. The output of the findings may be to create an action on the device, like shutting the appliance down (see Diagram 2).
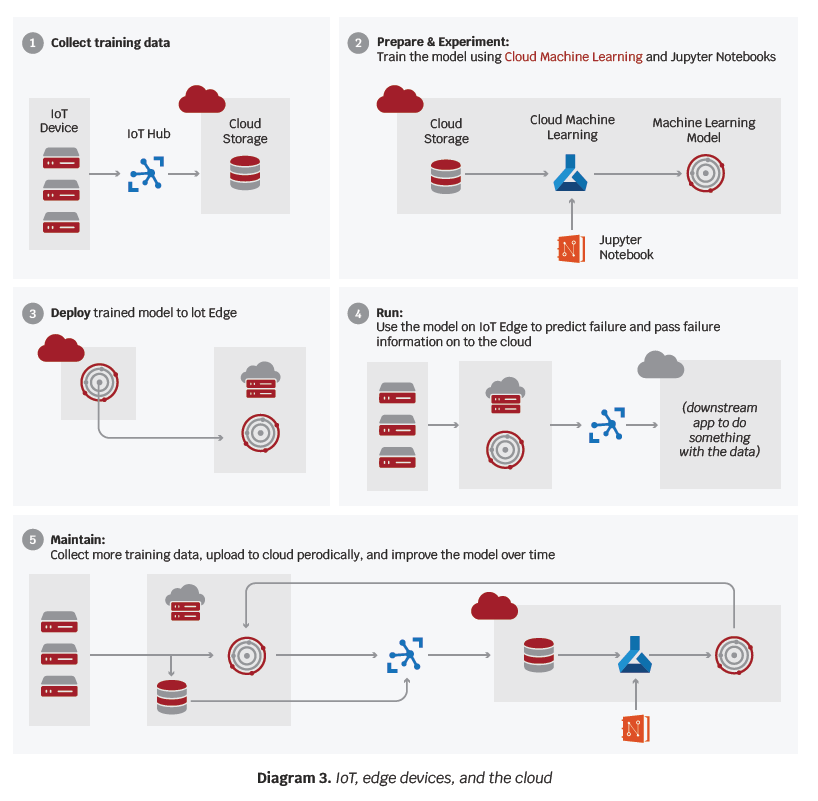
In Diagram 3, we have a typical use case of an IoT device monitoring machines to predict potential failures and shutdown. In this example, data is collected from the IoT device and transported to the cloud, which has a machine learning model to predict failure. This model is deployed to an IoT Edge device which monitors and, when needed, makes an action.
In this case, the processing of any additional incoming data will be performed at the edge. Latency is dramatically lower than in cloud processing. In addition to this, failure data is constantly uploaded back to the cloud to be combined with the older data and any additional big data available. The machine learning model is then further trained and updated with the new data. Should the model change significantly, it can then be pushed through and updated on the IoT Edge device. The cloud and big data are necessary for these processes, regardless of the ability to process data in the IoT edge.
Big Data
Big data is a combination of structured, semi-structured, and unstructured data collected and analyzed by organizations. Due to its large volume, velocity, and variety, it is nearly impossible to manage big data using traditional data processing software.
The global big data market is expected to grow at an 18% CAGR (Compound Annual Growth Rate) between 2021 and 2025, and reach about $90 US billion. The total amount of data created, captured, copied, and consumed globally is expected to surpass 180 zettabytes by 2025. The COVID-19 pandemic has a big role to play in this, with companies adopting remote work, becoming far more data-driven, and creating large amounts of video content e.g., recordings of virtual meetings and presentations.
The public cloud is an ideal low cost environment designed to handle the challenges of big data. As the use of big data increases, there is no doubt that this will generate additional innovation in cloud technology specific to this use.
The Internet of Things
The Internet of Things (IoT) is a collection of dataproducing devices that use an internet connection to transmit the collected data (e.g., temperature, speed, vibration) or conduct actions like controlling devices. Some IoT devices can have additional processing power that enables analysis and decision-making on the device itself, without having to transmit the data to the cloud first.
The IoT market is expected to grow at a CAGR of 27% from 2021 to 2025. Currently, there are approximately 10 IoT devices per household. The number is expected to reach 50 by 2025. This, combined with the massive amount of IoT devices deployed by businesses, will contribute 79.4 Zettabytes, to the total storage of around 180 ZB by 2025.

All in the Cloud
While it is possible to store and analyse data on premise or in a private cloud, this article focuses on the benefits of public cloud, with one of the main ones being low costs and the ability to scale as needed. An additional benefit of hyperscalers (AWS, Google, and Microsoft) is that they have an accelerated rate of development of new features and products that customers can use without having to develop them on their own.
A great example of this is Amazons Recommendation engine. This machine learning technology can be attached to any e-commerce site and configured to make recommendations to customers based on their selected purchases.
Amazon’s recommendation engine has led to 35% of all purchases made on Amazon.
IoT devices feed data into the cloud. There, the data is stored, classified, cleaned, and combined with other data sources. Then, it is analyzed either by big data platforms like Hadoop or native machine learning functionality that sits within the hyperscalers’ product line, e.g., Amazon SageMaker. The results can then be acted upon by either creating a feedback loop to the IoT device to create an action or alternatively it may inform a particular management decision e.g. comparing wear and tear in competing engine parts and making a decision on which one to go with.
With the growth of IoT devices and data feeding into the cloud, we would expect the growth in cloud to mirror the growth seen in these two technologies. IDC expects the CAGR of public cloud to be over 21.0% through 2025, reaching a total $809 US billion.
1+1+1=1000
It is clear to see the synergistic relationship between IoT, big data, and the cloud. While each component has its individual value, this value increases exponentially when they work in cooperation. Such technologies will only improve and get more affordable as their use increases. The ever-decreasing cost of IoT sensors and devices, coupled with the democratization of technology through the public cloud, makes these technologies affordable for smaller companies too.
While I have only looked as far as 2025 in this article, I have no doubt that the amount of devices, sensors, and data points will only continue on the current exponential growth curve. With more data feeding into the system, we gain more information and more knowledge, hopefully leading to greater insights and a better future for all.







