Language has been a defining characteristic of what makes us human and has served as a foundational tool for human expression, discovery, and invention. No one knows when spoken language first originated but estimates predict its first appearance among human tribes as far back as 150,000 years ago.
However, the earliest written form of human language dates as far back as 6,000 years ago located in southern Mesopotamia. Since the first signs of written language, we have seen humans evolve to use language to capture star formations in the night sky and write about them in caves, create stories and poems, novels and religious texts, songs and movie scripts, and turn language into its myriad of latent forms to represent mathematical structures of the universe, chemical interactions of subatomic particles, musical notation, hieroglyphics, and programming code that manipulate electrons on a physical processing unit in a mobile digital device.
The Rise of Language Models
The advent of the digital age in the 20th century brought about not just the invention of the digital computer but humanity’s endeavor to conquer the faculties of the mind. As such in the early 1950s, computer scientists such as Alan Turing, John McCarthy, and peers pioneered the era of Artificial Intelligence, bringing about innovations that would spawn a whole research field in the area of natural language processing.
The first conversational AI agent developed was known as Eliza, which imitated the language characteristics of a psychotherapist and was able to interact in simple conversation with another human, albeit with many flaws and many limited capabilities. Fast-forward to the present time, technology has advanced to the point where we are now reaching near-human level linguistic capabilities and great accuracy in summarizing texts, answering questions, extracting sentiment and entities, and many more NLP tasks.
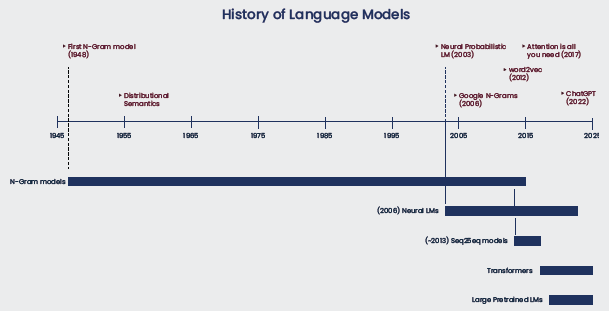
In 2017, Google published a paper called “Attention is All You Need”, in which it describes an Encoder-Decoder neural network architecture with a multi-head attention mechanism called the Transformer architecture. Previously, the industry relied on convolutional neural networks (CNNs) and sequential models like recurrent neural networks (RNNs), long short-term memory (LSTMs), and gated recurrent unit (GRUs) models for the majority of Deep Learning use cases.
As these models increased in architecture size, and as more and more data was used in training, it became evident that these models will require re-architecting to be able to leverage GPU parallelization and solve the problem of loss of contextual information over long sequences of words or tokens. In order to perform better at larger scales of data and keep track of context over long series of tokens, the self-attention mechanism was introduced, which is fundamental to the transformer model.
Enter GPT (Generative Pre-trained Transformer)
In 2018, Open AI released a paper called “Improving Language Understanding by Generative Pre-Training” which introduced the first version of the so called Generative Pre-trained Transformer (GPT) models that are trained on a large corpus of textual data in order to capture linguistic patterns which are then further fine-tuned for particular tasks, such as classification, summarization, and entailment or text generation.
The architecture of the GPT model varies from the traditional transformer model in which GPT uses a series of decoder-only blocks. Subsequently, Open AI introduced variants of GPT-1, such as GPT-2 in November 2019, which had over 1.5 billion parameters, culminating with GPT-3, which included over 175 billion parameters. To put this into perspective, it would take over 355 years to train a GPT-3 model on a single NVIDIA Tesla V100 GPU.
Open AI has forged a close collaboration with Microsoft on its AI efforts, and as part of this partnership Microsoft developed a supercomputer exclusively for Open AI to use, which contained over 285,000 CPU cores, 10,000 GPUs, and 400 gigabits per second of network connectivity between GPU servers to ensure maximum efficiency during training.
In November 2022, Open AI announced the launch of ChatGPT, a variant of GPT-3 which was fine-tuned on conversational text data and further fined-tuned using reinforcement learning with human feedback.
It is important to emphasize that none of these models have any understanding or intelligence. They are great pattern-matching algorithms that have learned linguistic representations from textual data at large scales.

Adoption of GPT and its Applications
The linguistic capabilities of models like ChatGPT and its applicability to various domains and industries is not to be understated.
ChatGPT has captured the imagination of the public, businesses, and organizations, and has reinvigorated the excitement around Artificial Intelligence. It took only five days for ChatGPT to reach 1 million users.
It was banned by StackOverflow which did not accept ChatGPT or GPT-generated answers, it prompted Google to issue a “code red” for its Search business, and many educational institutions and entire cities like New York City banned ChatGPT from its school computers and networks – effectively disabling access to teachers and students. What distinguished ChatGPT from its precursor GPT-3 is the user experience. In ChatGPT, the need to carefully craft the prompt was not necessary. Users could interact with it just like with any other human, by asking natural language questions and getting back relevant responses without losing context over long conversations. There have been many examples of people asking all sorts of creative questions. ChatGPT has been great at many tasks and failed to generate satisfactory results in others. Here are some areas where ChatGPT has demonstrated satisfactory results:
- Generating code for simple tasks e.g. Implementing the quick sort algorithm
- Fixing bugs in excerpts of code
- Writing poems
- Drafting emails
- Generate SQL commands from text
- Writing in the style of an actor or fictional character
- Content filtering by declining inappropriate requests (although there have been cases of “jailbreaks” or attempts to use clever prompt engineering to bypass these filters)
Here are some areas where further improvements can be made:
- Route suggestions
- Math
- Mixing fictional with factual content
- Hallucination and inaccuracies
- Limited knowledge – only trained on corpus data up to 2021
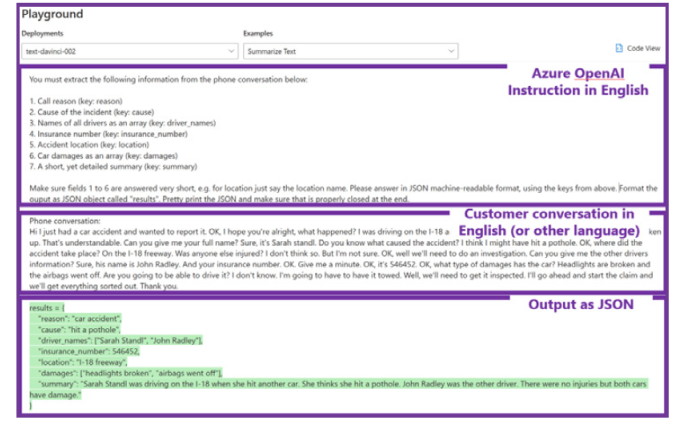
Other areas where GPT models can be used are text classification, entity extraction, summarization, text similarity matching and sentiment extraction, all of which can be applied in various scenarios across most European languages and within various industries. Here is an example of using Azure Open AI GPT-3 to extract salient pieces of information from a call transcript related to a road traffic accident.
Here is another example of Azure Open AI GPT-3 extracting key entities from a German piece of text using an English prompt:
- Any industry – Enhancing text-search using GPT-3 generated embedding
- Retail – Product and service feedback analysis
- Any industry – Customer and employee complaint classification
- Health and Financial Services – Claims and risk analysis
- Any industry – Support emails and call transcripts analysis
- Media and publishing – Social media analysis
- Marketing – Marketing campaign generation (emails, flyers, infographics, social media posts)
- Any industry – Competitive Analysis
- Any industry – Smart assistant in contact centers
Other industry use cases where GPT-3 can be applied to include but not limited to:
- Any industry – Classification of calls and routing to relevant teams
- Health – Extracting symptoms, diagnosis, drug dosage, administration method, drug type from patient notes and prescriptions
- Legal – Translating legal text in English and using it to populate Legal templates

The opportunities are endless when it comes to applying GPT-3 to industry use cases. Of course, any AI-based technology should undergo scrutiny in terms of abiding by responsible AI practices, ensuring that no harm can be inflicted directly or indirectly, and that careful prompt engineering is applied before any production system is integrated with its capabilities.
Potential Issues with Large Language Models
There are many risks and challenges with using Large Language Models, which are trained in an unsupervised fashion, in production. Many of these models will appear very confident in their answers without necessarily validating or fact-checking their responses which could result in factually incorrect answers that may seem correct at first sight.
The outcomes and responses generated by a large language model are autonomous in nature and there is no human intervention which poses a challenge from an accountability perspective.
Large language models will also enable anyone with a laptop and internet access to generate responses to exam questions, essay exercises, news articles, and other types of content, increasing the risk of plagiarism, and encouraging cheating in scenarios where text is the main form of input. Furthermore, there is a big risk of the possibility of using Large Language Models to automate certain roles and functions that involve natural language, such as:
- Customer service roles in contact centers, in front-desks, and other client-facing roles where communication is the primary modus operandi of the human employee
- Content generation which can automate the generation of blog posts, tweets on Twitter, news articles, and many other social media content
- Translation services operated by humans
- Data entry and processing roles which do not require deep domain knowledge and typically rely on a deterministic sequence of steps
- Quality assurance in software programming or any other technical field where human input is bounded by a set of parameters in accordance with a pre-defined set of quality standards
Large Language Models like GPT-3 and potentially future ones require large amount of computing power to complete training. This can potentially have detrimental environmental effects if done often and without proper supervision. This will be exacerbated as more and more companies follow the same pattern of developing large language models or Deep Learning models in general, which require a large amount of compute resources.
Future of Large Language Models
As ChatGPT and other Large Language Models (LLMs) continue to capture the imagination of the wider population, we are seeing a surge of businesses and organizations wanting to use the underlying technology of ChatGPT to drive new efficiencies and new ways of operating. Big heavy-weights like Microsoft and Google are heavily investing in these technologies in order to improve their products and services and increase their competitive edge in the market.
Microsoft recently announced its $10 billion investment in Open AI and is now integrating GPT-3 in most of its Office365 products, including its Bing search engine. Google announced the release of its ChatGPT competitor called Bard, also based on a Transformer-inspired neural network architecture called LaMDa.
As these models advance and incorporate more types of data (e.g. math textbooks, physics-related corpora, code, and other types of language expressions), we will be seeing a whole new world of applications arising which goes to show that we are only scratching the surface of what is possible. Continual learning, domain-specific information integration, and multi-modality are just some of the areas where language models will expand in the coming months and years.
“ChatGPT and conversational AI more broadly will continue to play an important role in various industries and have a significant impact on society.” – ChatGPT







